







Train Faster,喂饱每一张 GPU

让训练不再等盘:
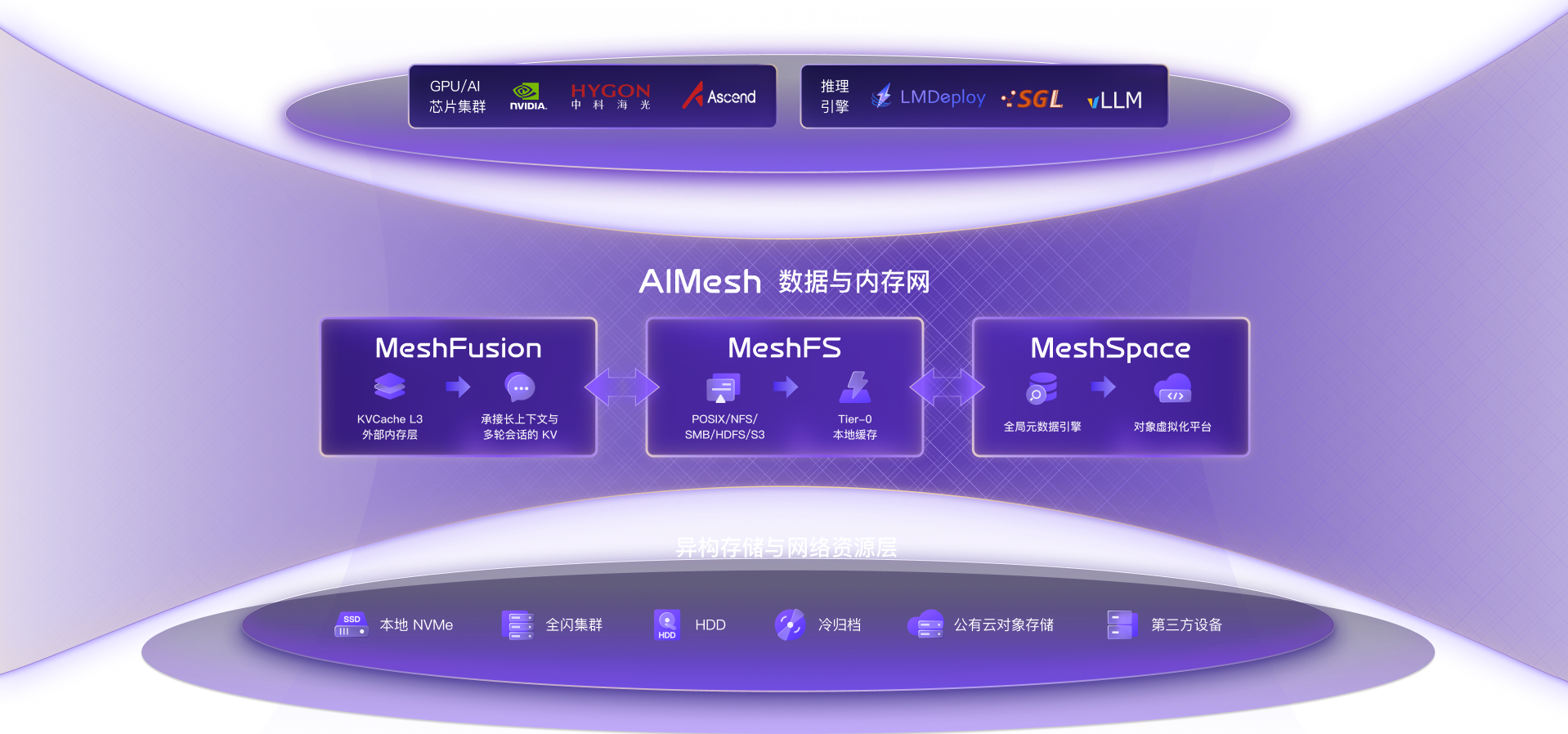
全闪 Shared-Everything 架构 + RDMA,消除单点热点。

Tier-0 本地缓存:
将热数据推到离 GPU 最近的地方,读延迟压至 20-30μs,单机吞吐达 50GB/s+。

多协议融合:
原生支持 POSIX, HDFS, S3,数据清洗与训练无需搬迁。

Infer Deeper,拆掉推理内存墙
KVCache L3 外部内存
将海量 KV Cache 卸载至高性能 NVMe 池,成本仅为 HBM/DRAM 的 1/100。

算存融合架构
消除网络瓶颈,性能可达 DRAM 的 90% 以上,稳定支撑超长上下文。

生态无缝兼容
即插即用对接 vLLM, SGLang, LMDeploy 等主流推理框架,模型无需修改。

Store Smarter,夷平数据

全局统一视图
通过全局命名空间,将跨地域、跨云的异构存储虚拟化为单一逻辑数据湖。
智能数据流动
基于访问热度,数据在高性能层(MeshFS)与低成本层(HDD/Cloud)间自动流转。

无限弹性扩展
纳管第三方存储与公有云对象,支撑 EB 级 AI 资产管理。

Train Faster,喂饱每一张 GPU
让训练不再等盘:
全闪 Shared-Everything 架构 + RDMA,消除单点热点。
Tier-0 本地缓存:
将热数据推到离 GPU 最近的地方,读延迟压至 20-30μs,单机吞吐达 50GB/s+。
多协议融合:
原生支持 POSIX, HDFS, S3,数据清洗与训练无需搬迁。

Infer Deeper,拆掉推理内存墙
KVCache L3 外部内存
将海量 KV Cache 卸载至高性能 NVMe 池,成本仅为 HBM/DRAM 的 1/100。
算存融合架构
消除网络瓶颈,性能可达 DRAM 的 90% 以上,稳定支撑超长上下文。
生态无缝兼容
即插即用对接 vLLM, SGLang, LMDeploy 等主流推理框架,模型无需修改。

Store Smarter,夷平数据
全局统一视图
通过全局命名空间,将跨地域、跨云的异构存储虚拟化为单一逻辑数据湖。
智能数据流动
基于访问热度,数据在高性能层(MeshFS)与低成本层(HDD/Cloud)间自动流转。
无限弹性扩展
纳管第三方存储与公有云对象,支撑 EB 级 AI 资产管理。








挑战
万卡训练 Checkpoint 写入导致长时间停顿。

成效
利用 MeshFS 将 Checkpoint 写入时间缩短 90%,GPU 停顿从分钟级压缩至秒级。

挑战
百万级 Token 上下文对 HBM 造成巨大压力。
成效
MeshFusion 稳定支撑长窗口,成本大幅降低。TTFT 仍优于纯 DRAM 方案。

挑战
海量小文件导入、数据清洗、训练间反复拷贝。
成效
实现从采集到训练的全流程数据零拷贝,极大加速模型迭代。









