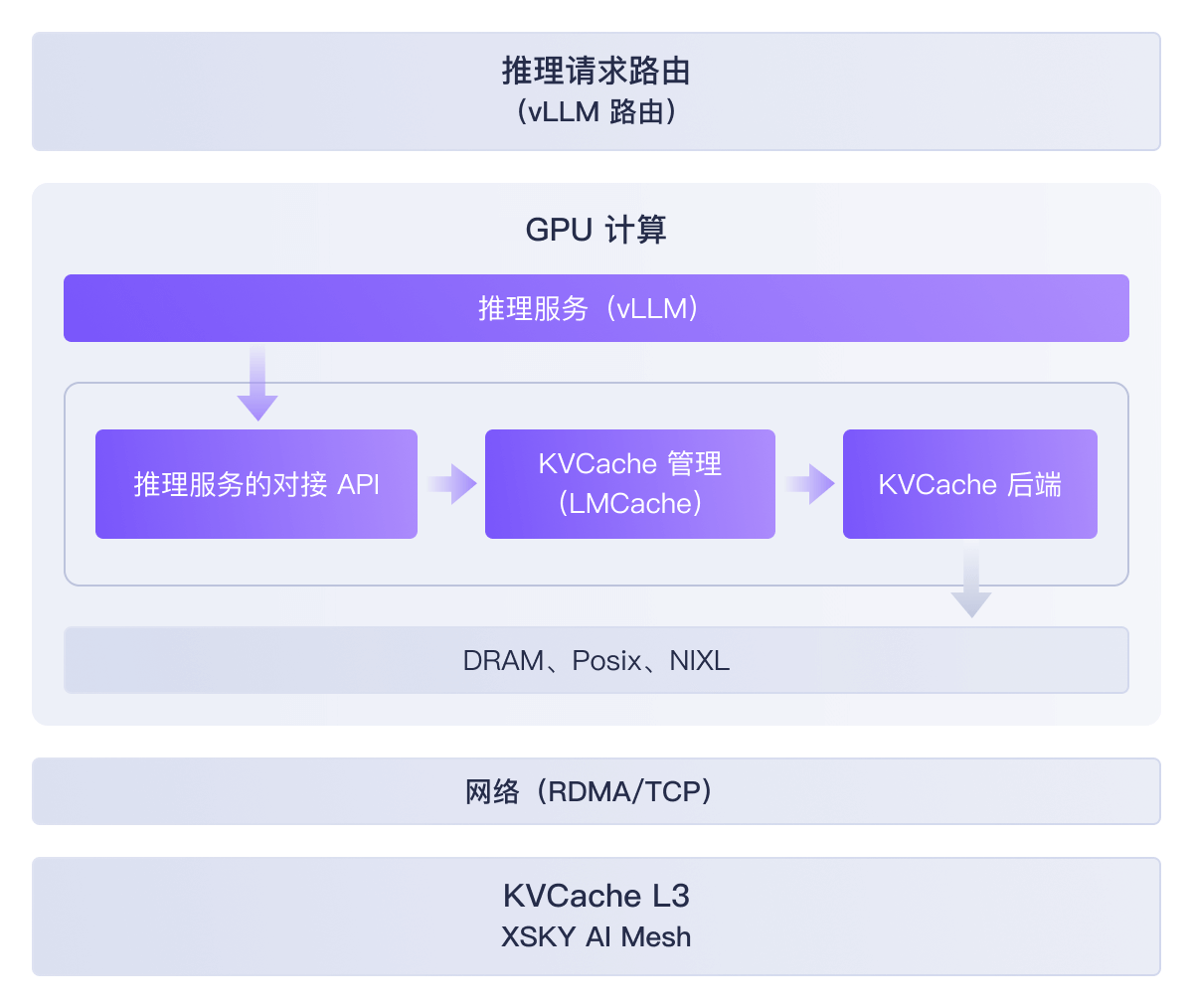
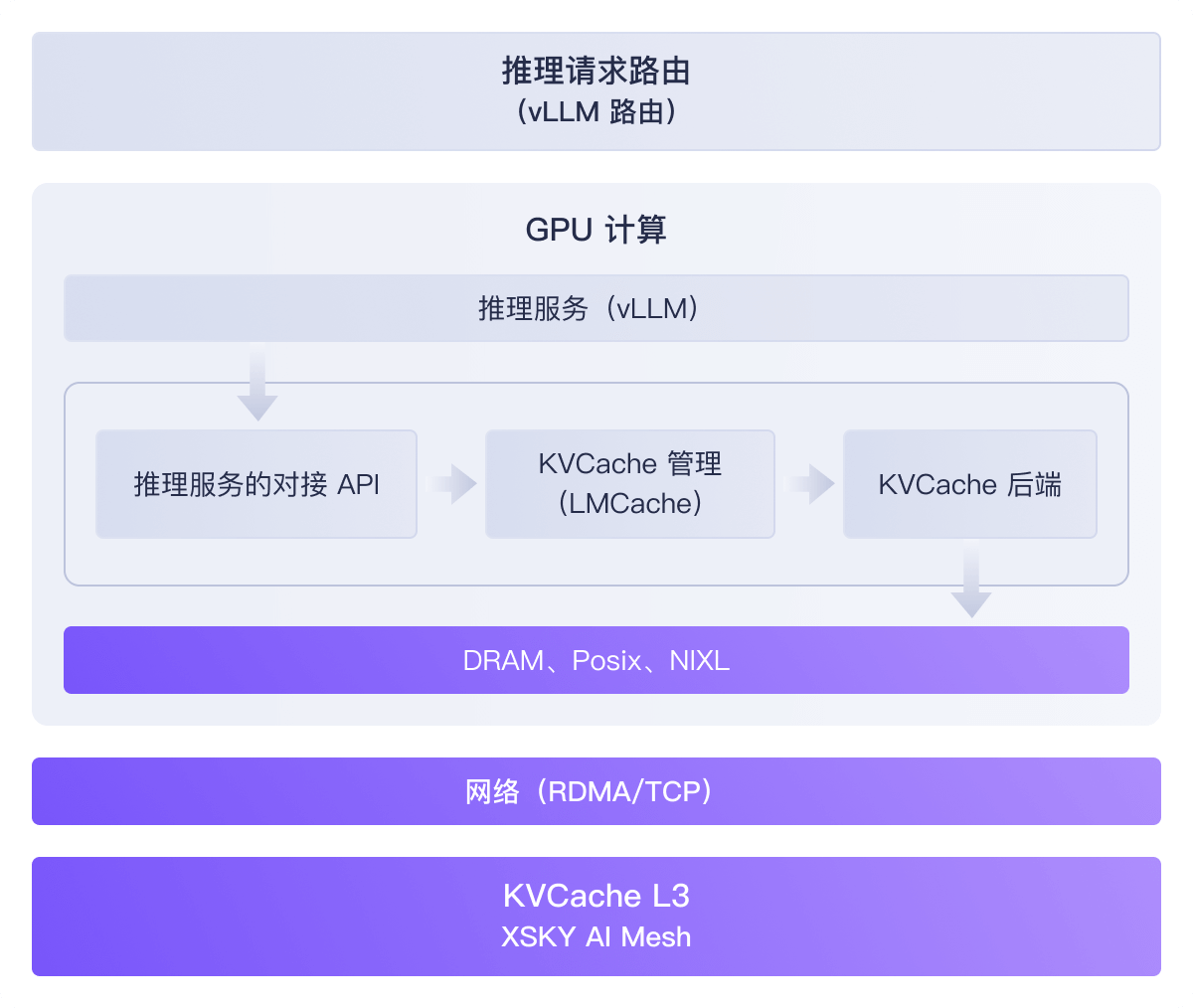
Shared-Everything 架构
所有GPU可以直接访问全局共享KVCache,突破单机显存限制,实现真正的弹性扩展。
40GB/s 带宽 & 100us 时延
全闪介质与优化的 IO 路径,实现接近 GPU 显存的性能,满足 KVCache 低延。
弹性水平扩展
按需扩展存储节点,性能随容量线性增长,轻松应对业务峰值与模型规模增。
无侵入性兼容主流框架
标准 POSIX 接口,无需修改模型代码和推理框架,即插即用,平滑迁移。