















推理服务兼容
vLLM, SGLang, NVIDIA Dynamo, LMDeploy

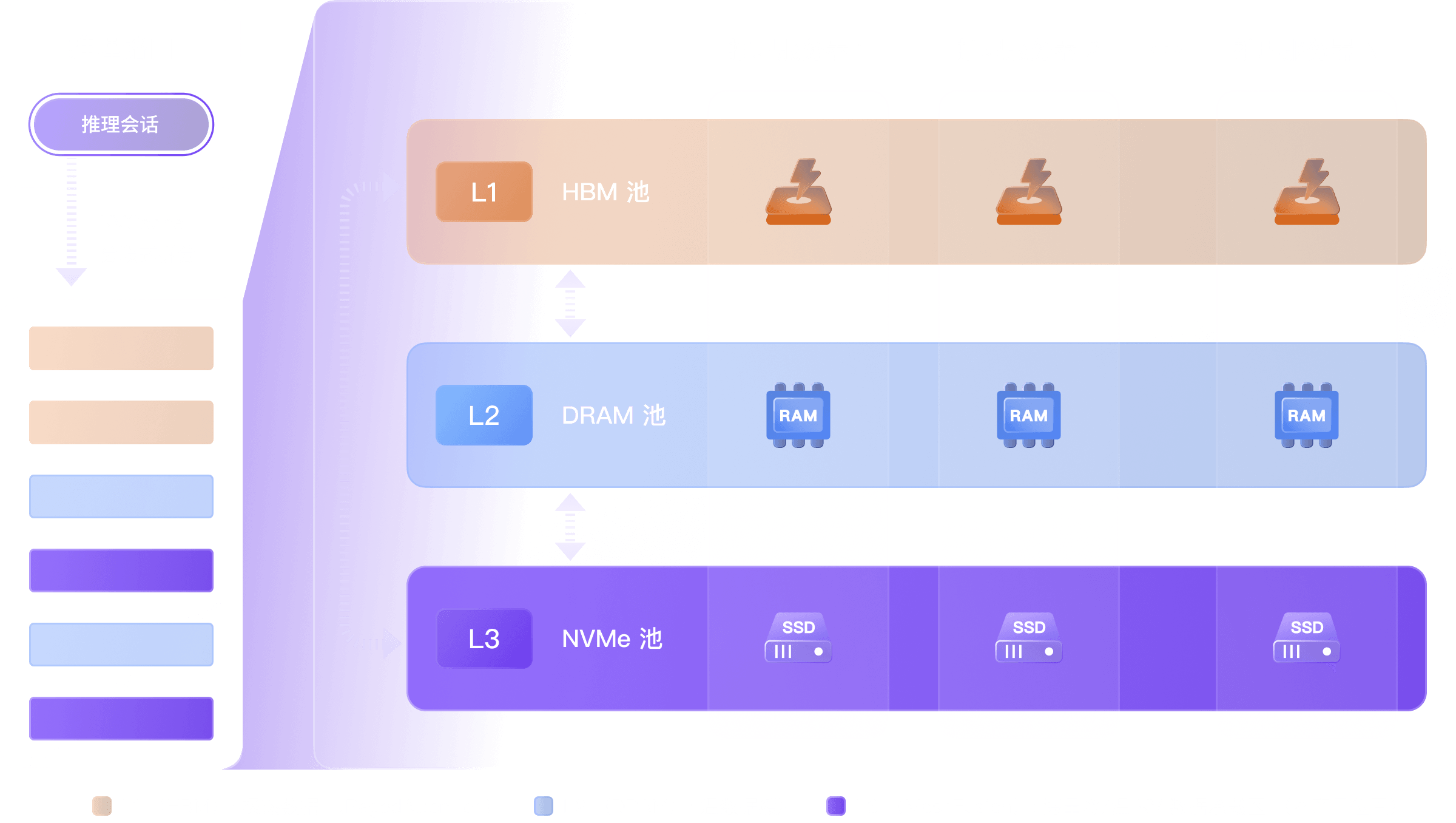
KVCache 框架适配
Mooncake, HiCache, LMCache

接口支持
POSIX, usrbio

硬件支持
广泛适配 NVIDIA 及国产 GPU 算力卡(华为 Ascend、寒武纪等)


场景
代码生成、复杂任务规划。

价值
持久化存储多轮对话的历史状态,无需重复计算,降低端到端延迟。

场景
法律合同审查、财报分析、书籍问答。
价值
低成本承载 128K~1M+ 超长上下文,避免显存溢出 (OOM)。

场景
云厂商 API 服务。
价值
在有限的 GPU 显存中并发服务更多用户,提升 ROI。









