






MeshSpace 选择了一条非侵入式的演进路线。
原地无感升级: 直接纳管您现有的 XEOS 集群。过去十年积累的 PB 级数据无需迁移,原地升级即可直接融入新的 AI 训练流,最大程度保护历史投资。
异构兼容并包: 强大的纳管能力,不仅支持自有存储,还能整合企业现有的第三方存储及公有云资源(如 AWS S3, Azure Blob),构建统一的混合云资源池。
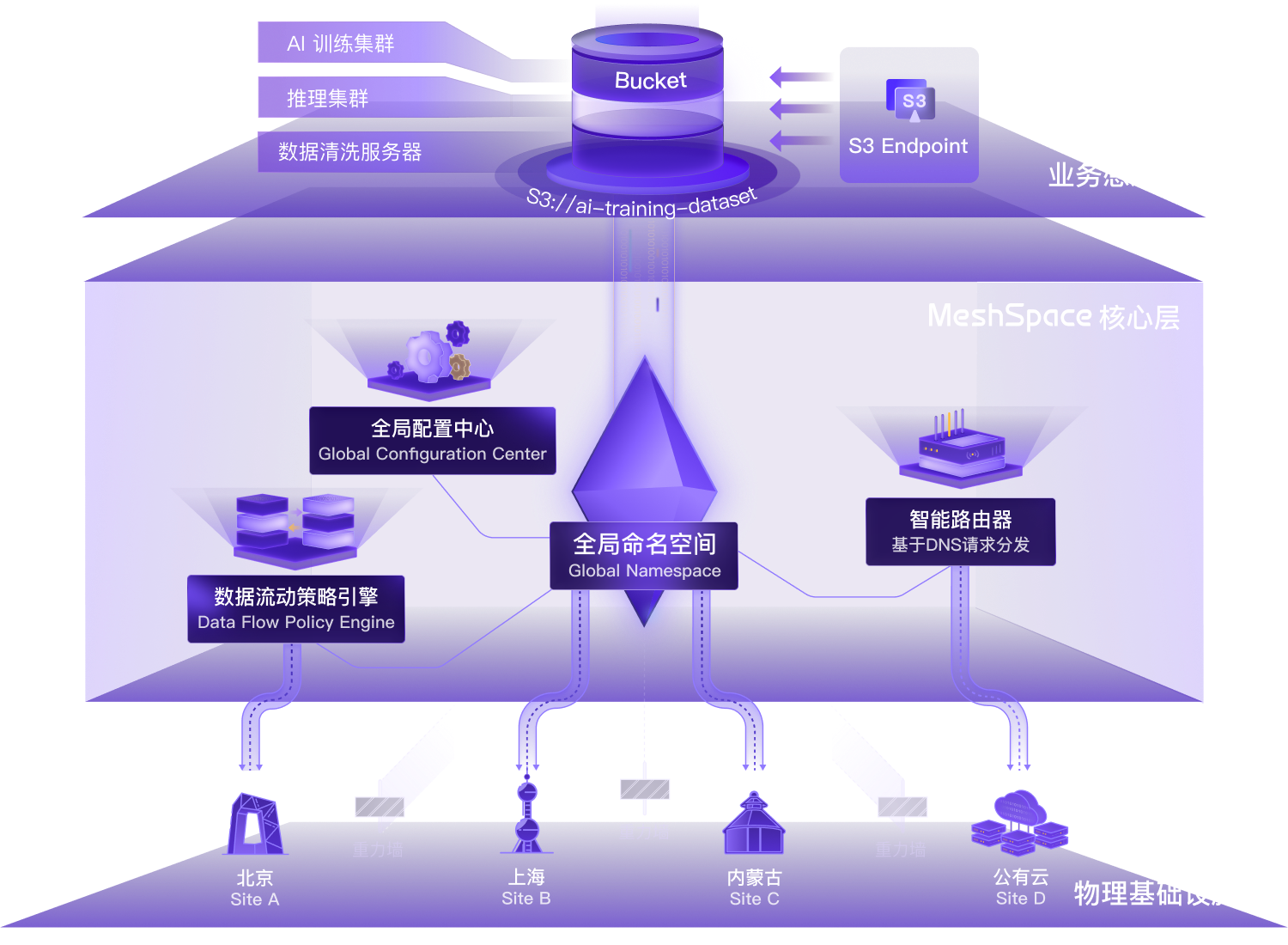
通过统一的 DNS 接入与全局路由,将分散在不同地域甚至云端的物理集群,抽象为一个逻辑整体。
单一入口体验: 无论底层有多少集群,业务端仅需面对唯一的 S3 Endpoint。彻底屏蔽底层 Cluster-A 或 Cluster-B 的物理细节,极大简化 AI 应用开发。
跨域透明访问: 即使 AI 训练任务在北京,数据存储在上海,系统也能自动定位并透明回源传输,实现“数据不动,逻辑互通”。
统一治理中心: 用户管理、配额分配(容量/带宽)及权限策略,全部在同一套控制面完成。管理员可轻松实现跨地域、跨集群的统一租户审计。
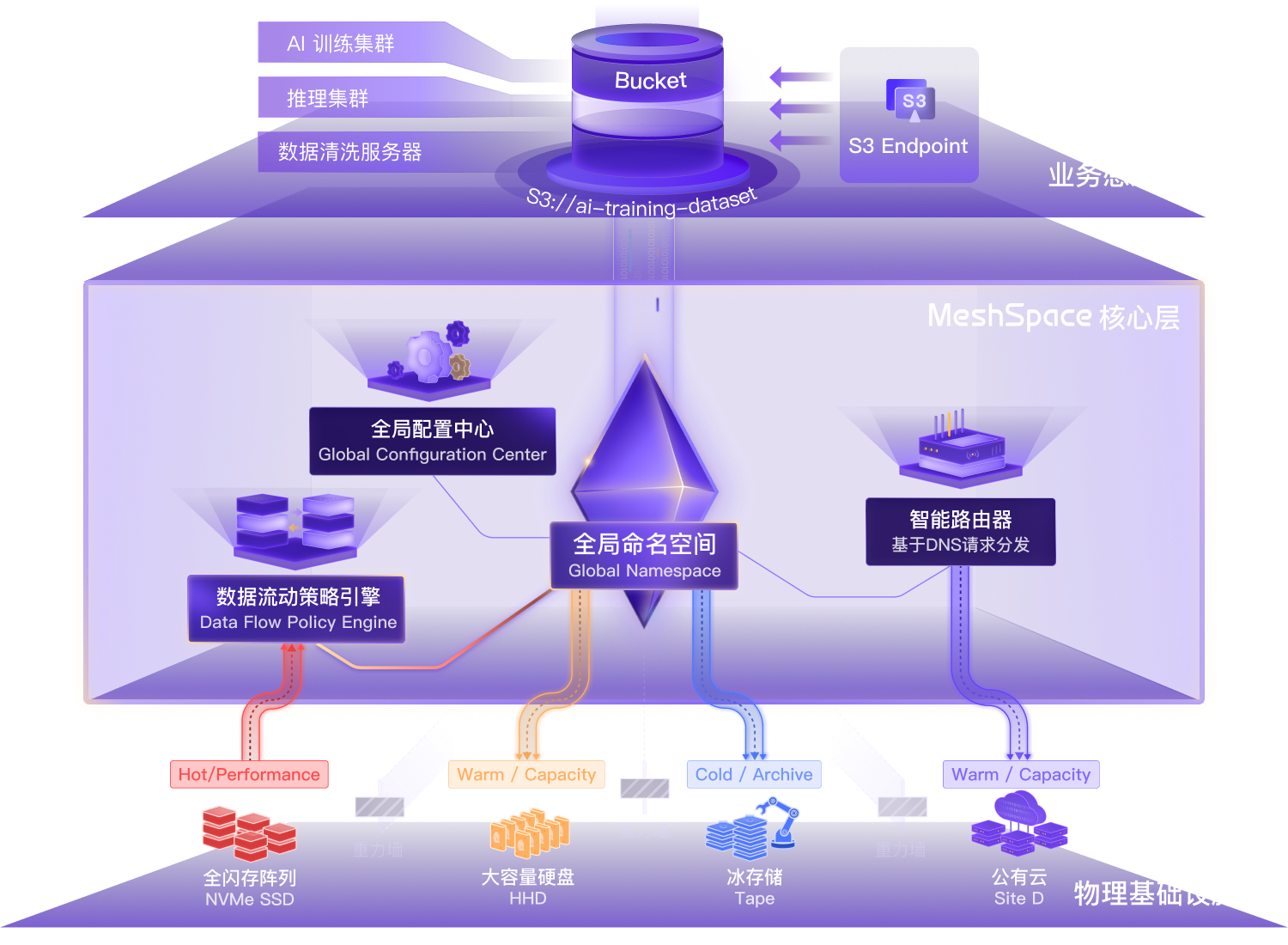
MeshSpace 打破了硬件的隔阂,支持异构存储平台的统一调度。数据不再是静态的,而是根据热度在全闪存、HDD 甚至磁带/公有云之间自由流动。
智能冷热分层: 依据 AIMesh Tiering 技术,系统自动分析数据热度。热数据(如 Checkpoint)自动上浮至全闪存池,冷数据(如历史语料)自动下沉至高密 HDD 或冰存储。
自动化流转: 让“热数据上得去,冷数据下得来”。无需人工干预,在保证业务性能的同时,实现存储成本的极致优化。

MeshSpace 选择了一条非侵入式的演进路线。
原地无感升级: 直接纳管您现有的 XEOS 集群。过去十年积累的 PB 级数据无需迁移,原地升级即可直接融入新的 AI 训练流,最大程度保护历史投资。
异构兼容并包: 强大的纳管能力,不仅支持自有存储,还能整合企业现有的第三方存储及公有云资源(如 AWS S3, Azure Blob),构建统一的混合云资源池。
通过统一的 DNS 接入与全局路由,将分散在不同地域甚至云端的物理集群,抽象为一个逻辑整体。
单一入口体验: 无论底层有多少集群,业务端仅需面对唯一的 S3 Endpoint。彻底屏蔽底层 Cluster-A 或 Cluster-B 的物理细节,极大简化 AI 应用开发。
跨域透明访问: 即使 AI 训练任务在北京,数据存储在上海,系统也能自动定位并透明回源传输,实现“数据不动,逻辑互通”。
统一治理中心: 用户管理、配额分配(容量/带宽)及权限策略,全部在同一套控制面完成。管理员可轻松实现跨地域、跨集群的统一租户审计。
MeshSpace 打破了硬件的隔阂,支持异构存储平台的统一调度。数据不再是静态的,而是根据热度在全闪存、HDD 甚至磁带/公有云之间自由流动。
智能冷热分层: 依据 AIMesh Tiering 技术,系统自动分析数据热度。热数据(如 Checkpoint)自动上浮至全闪存池,冷数据(如历史语料)自动下沉至高密 HDD 或冰存储。
自动化流转: 让“热数据上得去,冷数据下得来”。无需人工干预,在保证业务性能的同时,实现存储成本的极致优化。





痛点
北京团队需要使用上海数据中心的清洗结果进行训练,传统方式需手动拷贝,耗时费力。

解法
MeshSpace 全局命名空间让两地看到同一份数据视图。北京团队读取时,系统自动从上海回源,实现“数据不动,逻辑互通”。

痛点
自动驾驶积累了 PB 级原始素材,保留成本极高,但未来可能需要回溯用于 Corner Case 训练。
解法
利用生命周期策略,将历史素材自动沉降至 MeshSpace 的高密 HDD 池或冰存储中,在保证随时可读的前提下,大幅降低 TCO。

痛点
本地存储空间不足,或需要利用公有云算力进行突发任务处理。
解法
MeshSpace 纳管公有云对象存储,将云端作为扩展池或备份池。实现本地与云端数据的无缝流转与统一管理。









