
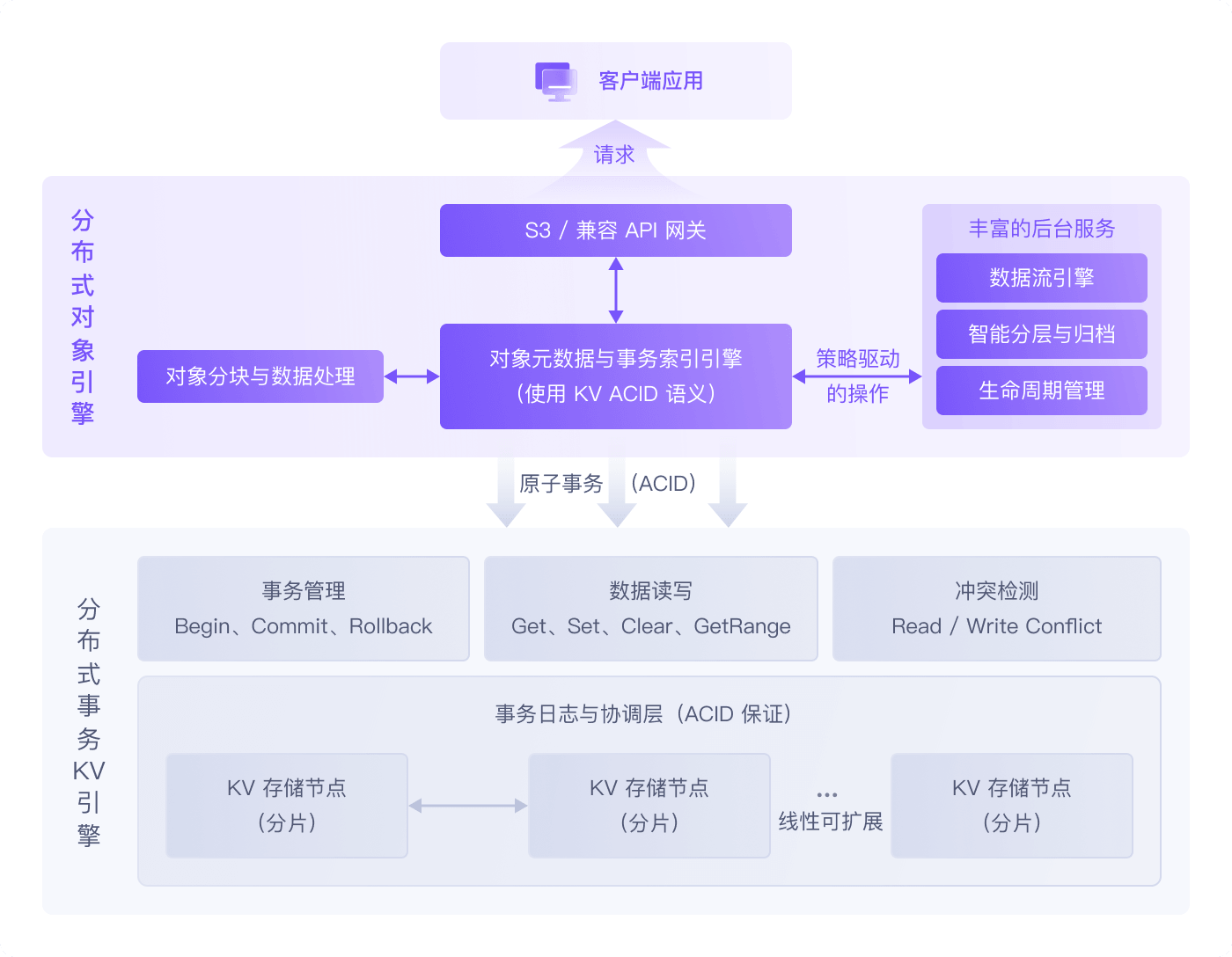

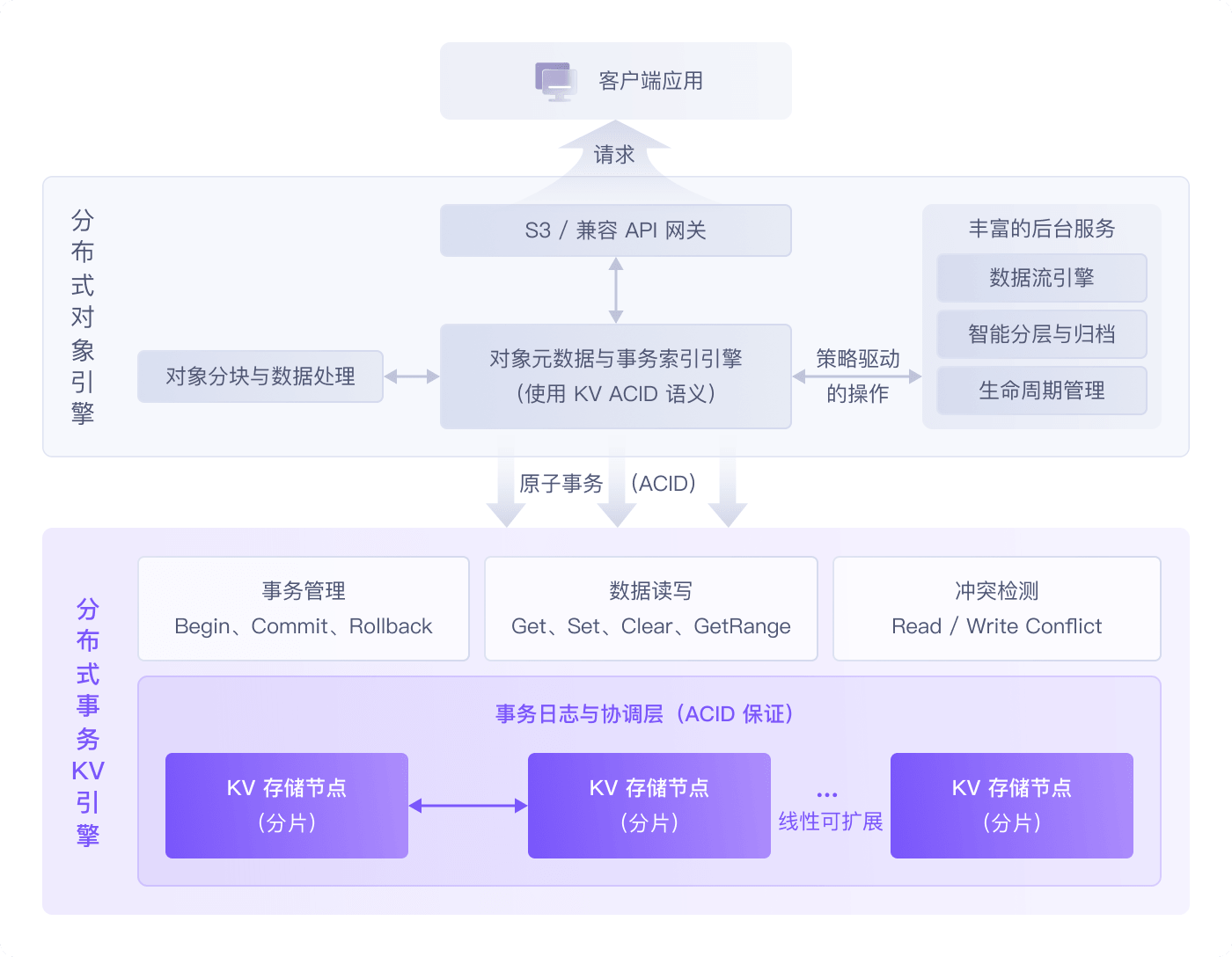


原生的 ACID 事务语义
基于内嵌事务型 KV 内核,将对象上传、属性修改或目录重命名等操作转化为分布式事务。确保在高并发或宕机异常下,元数据具备数据库级强一致性,告别最终一致性困扰。


丰富的索引能力
将对象元数据“扁平化”存储在内部 KV 引擎中,支持像文件系统一样按路径访问。同时可针对千亿级对象的 Tag、访问时间等特定字段进行高效排序与检索。

弹性的 KV 扩展
分布式 KV 引擎集群随存储节点扩容而横向扩展,性能也随之增长,保证了元数据性能与存储容量的线性同步增长,避免出现“容量充足但慢得无法使用”的弊端。


元数据冷热分层
支持将热元数据保留在 KV 引擎中,冷元数据归档到底层数据池,只保留轻量标记,使 KV 引擎不再长期承载冷数据元信息压力,从根本上优化元数据层 TCO。